
10:00 AM ~ 12:00 PM Room 4004
Seokheon Cho, ph. D. / Principal Network Architect
Overview of Artificial Intelligence
● Artificial Intelligence (AI)
- Supervised Learning (지도 학습)
- Unsupervised Learning (비지도 학습)
- Reinforcement Learning (강화 학습)
● Artificial Intelligence Frameworks (AI 프레임워크)
- Top 7 Artificial Intelligence Frameworks (TOP 7)
● Performance Metrics (분류 모델 평가 지표)
- Numerical Analysis (수치 분석)
- Classification (분류)


Step 1
Gathering data from various sources
- 다양한 데이터 수집
Step 2
Cleaning data(데이터 전처리) to have homogeneity
- 데이터 전처리로 동질성 찾기
- 보통 전체의 70%를 차지하며, 통찰력이 있어야하며 단순하고 어려워 대부분 하기 싫어함.
Step 3
Model Building(모델링)-Selecting the right ML algorithm
- 옳은 머신러닝 알고리즘으로 모델링
Step 4
Gaining insights from the model`s results
- 모델링 결과로부터 인사이트 얻기
Step 5
Data Visualization(데이터 시각화)-Transforming results into visuals graphs
- 데이터 시각화 - 결과를 시각적 그래프로 변환
Supervised Learning
● 정답이 있는 데이터를 활용해 데이터를 학습
● 대표적 분류
- Classification (Input -> Label) 분류
- Regression (Input value -> Output value) 회귀

apple, mango, pear들이 있는 raw data를 input 한다.
supervised learning은 정답이 있기 때문에 algorithm으로 processing 하면 apple, mango, pear이 나옴
즉, set이 지정된 데이터를 머신 러닝 모델에 입력한다. 모델은 알려진 입력 및 출력 데이터로 학습되므로 이에 따라 향후 출력을 예측할 수 있다.
Unsupervised Learning
● 정답이 없는 데이터를 비슷한 특징끼리 군집화
- 새로운 데이터에 대한 결과를 예측하는 방법
● 대표적 종류
- Clustering (군집 분석)
- Association (연관 분석)
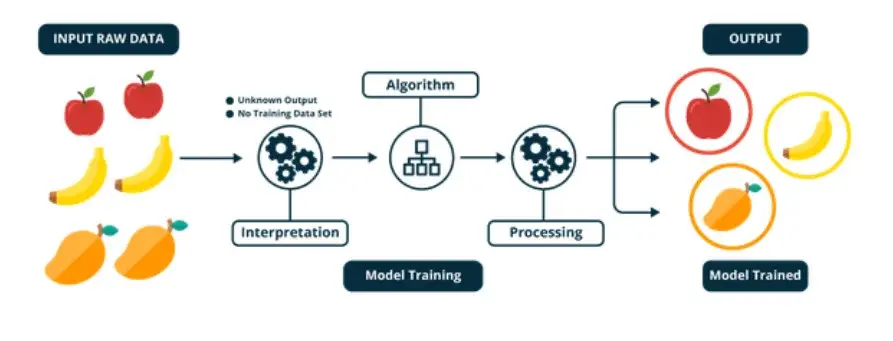
apple, banana, orange의 raw data를 받는다. 여러가지 예측이 있겠지만 하나의 예시로 색깔에 따른 분류로 학습을 시켜 결과를 도출하거나, 혹은 원, 타원, 길이 등으로 분류를 시키는 등이 비지도 학습이다.

EX1) customer1 - bread, milk, fruits, wheat를 구매
EX2) customer2 - bread, milk, rice, butter를 구매
EX3) customer3 - ......
...
...
EXn) customerN = if a new customer purchases bread, he is likely to purchase milk too와 같이 정답은 없지만 예측을 할 수 있다.
-> 마트의 기저귀 코너 옆에 맥주가 비치되어 있는 것은 아빠들이 아기 심부름을 갈 때의 심리를 이용한 것
Reinforcement Learning
● 시행착오(Trial and Error)를 통해 학습하는 방법
- 실수와 보상을 통해 학습을 하여 목표를 찾아가는 알고리즘
● 대표적 종류
- Markov Decision Process (마르코프 의사결정 과정)
○ 불확실한 상황에서 의사결정을 하려면 확률에 기초하여 분석을 해야한다. 어떤 사건이 발생할 확률 값이 시간에 따라 변화해 가는 과정을 확률적 과정이라고 하며, 확률적 과정 중에서 한 가지 특별한 경우가 마르코프 과정이다.
○ 마르코프 과정은 어떤 상태가 일정한 간격으로 변하고, 다음 상태는 현재상태에만 의존하며 확률적으로 변하는 경우의 상태의 변화를 뜻한다. 즉, 현재 상태에 대해서만 다음 상태가 결정되며, 현재 상태에 이르기까지의 과정은 고려할 필요가 없다.
○ 예를 들어 자율주행에 쓰이는데 이때 자율주행 자동차에 들어갈 알고리즘을 만든다고 할 때, 가장 중요한 문제 중 하나는 확률계에서 순차적 의사결정 문제를 푸는 것이다. 이때 예상과 일치하지 않는 상황을 확률계라 한다.
○ 마르코프 결정 과정은 동적 계획법과 강화 학습 등의 방법으로 푸는 넓은 범위의 최적화 문제에 유용한 도구로 활용되며, 로봇 공학, 제어 자동화, 경제학, 제조업 등의 영역에서 폭넓게 사용되고 있다.
- Dynamic Programing (동적 계획법, 동적 프로그래밍)
○ 수학과 컴퓨터 과학, 그리고 경제학에서 동적 프로그래밍이란 복잡한 문제를 간단한 여러 개의 문제로 나누어 푸는 방법을 말한다. 이것은 부분
Artifical Intelligence Frameworks

Scikit-learn (파이썬을 대표하는 머신러닝 라이브러리)
● 프랑스 데이터 과학자인 David Couranpeau가 2007년에 공개
- stable release : 2021년 12월 25일에 version 1.0.2 공개
● 공식 홈페이지 : http://scikit-learn.org/stable/
scikit-learn: machine learning in Python — scikit-learn 1.2.0 documentation
Model selection Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning Algorithms: grid search, cross validation, metrics, and more...
scikit-learn.org
● 특징
- python을 대표하는 Machine learning library
● 지원 소프트웨어
- python 기반
● 장점
- Machine learning algorithms 및 model들이 구현
- 예제와 사용 설명서 풍부
● 단점
- Deep learning이나 reinforcement learning 지원하지 않음
- Graphic model이나 sequence prediction 지원하지 않음
Theano (딥러닝 초점)
● 최초의 인공지능 프레임워크 (2010년 공개)
● 공식 홈페이지 : http://deeplearning.net/software/Theano/
https://theano-pymc.readthedocs.io/en/latest/#
Welcome — Theano 1.1.2+29.g8b2825658.dirty documentation
How to provide help If you see a question on the theano-users mailing list, or on StackOverflow, that you feel reasonably confident you know an answer to, please do support the community by helping others. We were all newbies to Theano once and, as the com
theano-pymc.readthedocs.io
https://pypi.org/project/Theano/
Theano
Optimizing compiler for evaluating mathematical expressions on CPUs and GPUs.
pypi.org
● 특징
- 다차원 배열에서의 연산을 효율성과 정밀성을 갖춰 계산 가능
● 지원 소프트웨어
- python 기반
● 장점
- GPU 연산과 OpenMP 지원
- 딥러닝 알고리즘을 python으로 쉽게 구현 가능
- Keras와 같은 라이브러리를 함께 사용하여 프로세스를 단순화
● 단점
- 다른 프레임워크와 달리 확장성이 높지 않음
- 대학원 연구실에서 개발하여 유지보수가 좋지 않음
Caffe
● Yahoo에서 2013년에 공개한 프레임워크
● 공식 홈페이지 : http://caffe.berkeleyvision.org/
Caffe | Deep Learning Framework
Caffe Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR) and by community contributors. Yangqing Jia created the project during his PhD at UC Berkeley. Caffe is released un
caffe.berkeleyvision.org
● 특징
- 표현, 속도 및 모듈성을 염두
- TensorFlow가 공개되기 전 가장 인기가 많은 프레임워크
● 지원 소프트웨어
- Python, C++, Matlab 인터페이스
● 장점
- 최신 CNN을 이용하여 이미지 분류에 적합한 프레임워크
- Caffe의 Model Zoo에서 사전 학습된 모델을 이용하여 코드 작성없이 모델 훈련 가능
● 단점
- 텍스트 및 사운드 등의 비정형 데이터 처리에는 부적합
Torch
● 미국 뉴욕대학교에서 2014년에 만들어져서 Facebook이 확장시킨 프레임워크
● 공식 홈페이지 : http://torch.ch/
Torch | Scientific computing for LuaJIT.
Torch is a scientific computing framework for LuaJIT.
torch.ch
● 지원 소프트웨어
- C, C++, Lua
● 장점
- 최대 유연성 제공을 목표
--> 결합하기 쉬운 모듈 조각 존재
- 쉬운 Neural network의 layer 유형을 작성 및 GPU 실행
- 기존 모델 활용 용이 : 사전에 학습된 모델 존재
TensorFlow
● 구글 브레인팀에서 2015년 11월에 공개한 인공지능 프레임워크
● 공식 홈페이지 : https://www.tensorflow.org/
TensorFlow
모두를 위한 엔드 투 엔드 오픈소스 머신러닝 플랫폼입니다. 도구, 라이브러리, 커뮤니티 리소스로 구성된 TensorFlow의 유연한 생태계를 만나 보세요.
www.tensorflow.org
● 지원 소프트웨어
- C, C++, Python
● 장점
- 산업용으로 만들어진 프레임워크 (전문성 보장)
- 방대한 user community와 document 존재
- Theano 대체 프레임워크
--> Theano보다 컴파일 시간이 빠르며 데이터 및 모델 병렬 처리 가능
● Torch보다 복잡하지만 더 많은 기능 보유
● 단점
- 전체적으로 다른 프레임워크보다 연산 속도 느리고 메모리를 효율적으로 사용하지 못하고 있음
Keras
● 구글에서 2015년에 공개한 프레임워크
● 공식 홈페이지 : https://keras.io/
Keras: the Python deep learning API
State-of-the-art research. Keras is used by CERN, NASA, NIH, and many more scientific organizations around the world (and yes, Keras is used at the LHC). Keras has the low-level flexibility to implement arbitrary research ideas while offering optional high
keras.io
● 특징
- Opensource neural network library
● 지원 소프트웨어
- Python, R
● 장점
- TensorFlow, Theano, DL4J 및 MXNet과 함께 사용 가능
--> Theano와 TensorFlow를 back-end로 사용하는 deep learning library
- Torch와 유사하게 직관적인 API 제공
--> 고급 모듈을 조합하여 쉽게 신경망 설계 가능
--> 다양한 함수 제공하여 쉬운 customizing
● 단점
- Theano 프레임워크에서 문제가 발생 시 디버깅 어려움
CNTK
● 마이크로소프트에서 2016년에 공개한 프레임워크
● 공식 홈페이지 : https://github.com/microsoft/CNTK/
GitHub - microsoft/CNTK: Microsoft Cognitive Toolkit (CNTK), an open source deep-learning toolkit
Microsoft Cognitive Toolkit (CNTK), an open source deep-learning toolkit - GitHub - microsoft/CNTK: Microsoft Cognitive Toolkit (CNTK), an open source deep-learning toolkit
github.com
● 지원 소프트웨어
- Python, C++
● 특징
- DNN (Deep Neural Network), CNN (Convolution Neural Network) 및 regression 등의 알고리즘 포함
- GAN (Generative Adversarial Networks) 구현 용이
Numerical Analysis
● MAE (Mean Absolute Error) = (평균 절대 오차)
- 해석에 용이 : 가장 직관적
- 모델이 Underperformance / Overperformance 인지 판단 불가능
● MSE (Mean Square Error) = (평균 제곱 오차)
- Outlier (특이점)에 민감
● RMSE (Root Mean Square Error) = (루트 평균 제곱 오차)
- Outlier (특이점)에 민감
- 큰 에러에 대해 크게 페널티를 주는 이점 존재
- Machine learning의 학습에 있어서 특이점들에 휘둘리지 않는 게 가장 중요한 사항

MAE와 MSE의 예시



위의 MSE처럼 기본으로 주어진 값인 31/4가 있는 반면 x=6 y=100이 추가되어 계산할 경우
MSE는 6500/5의 값이 나온다. 이때 값의 gap이 커지기 때문에 RMSE를 사용
Classification
● Confusion matrix (혼동 행렬)
- True : 예측값과 실제값이 동일
- False : 예측값과 실제값이 상이
- Positive : 예측값이 1으로 분류되는 클래스 (class)
- Negative : 예측값이 0으로 분류되는 클래스
True Positive (TP)
- 1으로 예측하고 실제값도 1임
- 예측값과 실제값이 동일
False Positive (FP)
- 1으로 예측했지만 실제값은 0임
- 예측값과 실제값이 상이
True Negative (TN)
- 0으로 예측하고 실제값도 0임
- 예측값과 실제값이 동일
False Negative (FN)
- 0으로 예측했지만, 실제값은 1임
- 예측값과 실제값이 상이

1. 컷오프 번호 이상의 기록은 "1"로 예측된다.
2. 컷오프 번호 이하의 기록은 "0"으로 예측된다.
3. 평가 데이터소스의 모든 참 대답은 "0"
4. 평가 데이터소스의 모든 참 대답은 "1"
5. 줄무늬 영역은 선택한 컷오프를 기준으로 정답이 잘못 예측된 레코드를 나타난다.
classification
| prediction (예측값) | |||
| Positivie (1) | Negative (0) | ||
| Actual value (실제값) |
Positive (1) | TP | FN |
| Negative (0) | FP | TN | |
● Accuaracy (정분류율)
- 전체 데이터 중 정답을 제대로 예측한 것의 비율
- (TP + TN) / (TP + FP + TN + FN)
● Error rate (오분류율)
- 전체 데이터 중 오류의 비율
- (FP + FN) / (TP + FP + TN + FN) == 1 - Accuaracy
● Sensitivity (민감도)
- 실제값이 positive인 데이터 중 positive로 예측된 데이터의 비율
-> True positive rate (TPR)
- TP / (TP + FN)
● Specificity (특이도)
- 실제값이 negative인 데이터 중 negative로 예측된 데이터의 비율
-> True Negative rate (TNR)
- TN / (FP + TN)
- 민감도와 특이도는 잘 예측된 확률을 보여줌
- 민감도와 특이도는 함께 높을수록 좋지만, trade-off 관계성 지님
● Precision (정밀도)
- Positive라고 예측한 것들 중에서 실제 값이 positive인 것들의 비율
- TP / (TP + FP)
● Recall (재현율)
- Positive로 정답을 가지는 데이터 중 positive로 예측된 데이터의 비율
- TP / (TP + FN)
- 정밀도와 재현율은 positive에 초점을 둔 지표
- 정밀도와 재현율은 함께 높을수록 좋지만, trade-off 관계성 지님
● F1 Score
- Precision과 recall의 harmonic mean (조화 평균값)
- 2 * (Precision * Recall) / (Precision + Recall)
-> 최대 1의 값을 가짐
-> Precision과 recal이 모두 높을수록 1에 가까운 값을 가짐
● ROC (Receiver Operating Characteristic) curve 및 AUC (Area Under the Curve) Score
- Balanced data (균형 데이터)를 대상으로 할 때 사용하는 지표
- FPR(False Positive Rate : 1 - TNR)이 변함에 따라 TPR(True Positive Rate)이 어떻게 변하는지를 나타내는 곡선
- AUC 값은 ROC 곡선 아래의 면적
- 성능이 좋은 예측 모델
-> ROC가 좌측/위에 가까울수록
-> AUC값이 1에 가까울수록

● PR (Precision-Recall) curve 및 AUC (Area Under the Curve) Score
- Unbalanced data (불균형 데이터)를 대상으로 할 때 사용하는 지표
- AUC 값은 PR 곡선 아래의 면접
- 성능이 좋은 예측 모델
-> AUC 값이 1에 가까울수록
