
10:00 AM ~ 12:00 PM ROOM 4004
Project Search
14:30 AM ~ 15:30 PM Room 4004
Seokheon Cho, ph. D. / Principal Network Architect
Data Preprocessing in KNIME
데이터 조인(Joiner)
● 두 개의 테이블에서 지정한 키 변수를 기준으로 조인
- 새로운 테이블 생성
● Nodes : Excel Writer
● Join mode

- Inner Join, Left Outer Join, Right Outer Join, Full Outer Join
● Inner Join
- 두 테이블에서 키 변수 (ID) 값이 동일한 행만 조인
● Left Outer Join
- 첫 번째 테이블의 키 변수와 일치하는 값을 가지는 두 번째 테이블의 행을 붙여줌. 일치하지 않는 키 변수에 해당하는 값은 결측값
● Full Outer Join
- 두 테이블의 키 변수가 일치하는 행은 두 테이블의 값으로 붙여줌. 일치하지 않는 행의 값은 결측값
ex)
Table1은 Customers.csv
Table2는 Orders.csv
각각의 테이블 노드를 만든다.
CSV Reader -> F6 -> CSV -> F7


joiner 노드로 두개의 테이블을 연결한다.



Joiner -> F6 -> Add mathcing criterion -> 원하는 조인 선택

두 개의 테이블에서 Customer ID만 표출하고 Right Outer Join을 해보자


Column Selection에서 Customer ID만 표출하도록 한 후 F7 -> Join Result를 보면

홈페이지 가입과 구매를 동시에 한 ID의 Rows가 803인 것을 알 수 있다.

위와 같이 할 Left outer join을 할 경우

Rows가 832가 나온다. 즉, 홈페이지에 가입한 인원은 832명이지만 실제 구매까지 한 인원은 830명이고 2명은 가입만 하였고 주문까지는 안한 고객을 확인할 수 있다.
ex)
첫 번째 테이블은 Customer ID, City, Region으로 하고 두 번째 테이블은 Freight로 해보자. Joiner -> F6


F7 -> Joiner Result를 보면

주문 고객에 따른 배송 무게를 확인 할 수 있다.

테이블 읽고 쓰기
● Node : Table Writer
- Joiner를 통해 출력된 데이터를 .table 파일을 생성하여 로컬 컴퓨터에 저장
● Node : Table Reader
- .table 파일을 다시 가져오는 노드
ex)
두 테이블에서 Customer ID만 뽑은 Joiner파일과 Table Writer를 연결 -> F6 -> F7

ex)
Table Writer를 통해 내보낸 Table 파일을 다시 불러보자. Table Reader -> F6 -> F7


데이터 셔플
● 임의의 순서로 행을 재배열
● Node : Shuffle
ex) Shuffle 노드 -> F6 -> Use seed 체크 -> 셔플할 수 입력 -> F7 -> Shuffled를 통해 확인



데이터 연결
● 두 개의 테이블을 결합하여 새로운 테이블 생성
● Node : Conceatenate
ex)
table1에는 Customer.csv를 table2에는 order.csv 파일을 넣은 노드를 생성한다. Concatenate 노드를 불러서 각 테이블을 연결한다.
ex-1)
Skip Rows를 선택할 시 / Use union of columns

Concatenate -> F6 -> F7 -> Concatenated table
- Order 테이블의 830개의 행만 존재하게 된다. / 두 테이브레 정의된 모든 행이 출력

*customer 행은 832개 order 행은 830개 중에서 겹치는 것만 출력되는 듯?
ex-2)
Append Suffix를 선택할 시 / Use union of columns
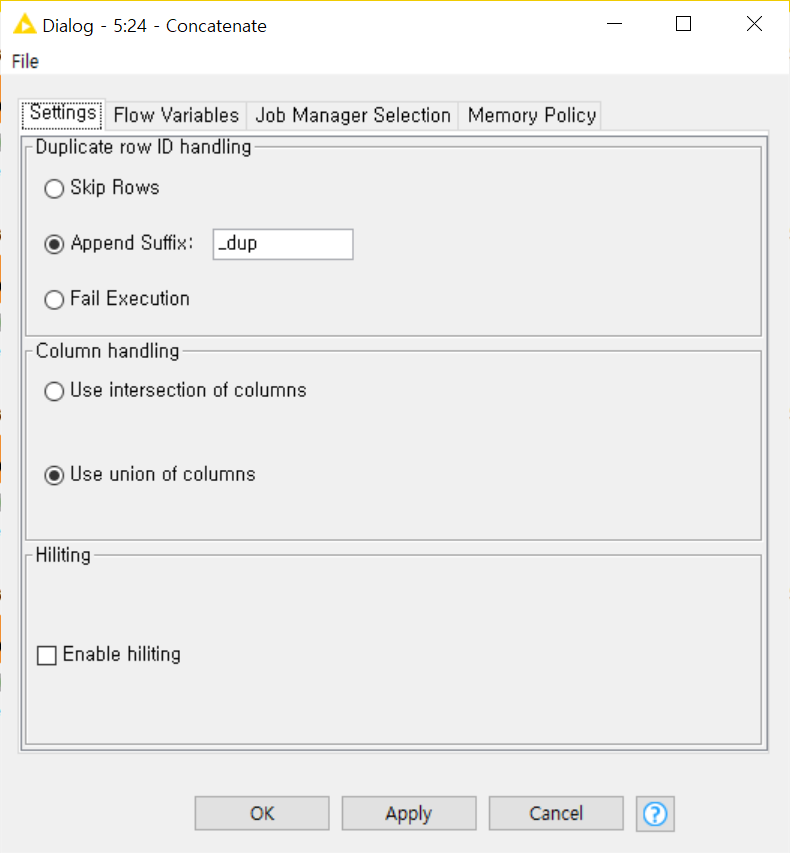
Concatenate -> F6 -> F7 -> Concatenated table
- Order 테이블의 830개와 Customer 테이블의 91개의 행이 합쳐져서 출력

- Order 테이블의 830개와 Customer 테이블의 91개의 행이 합쳐져 921행이 나오며 Row*_dup로 표시
ex-3, 4)
Skip Rows, Append Suffix를 선택할 시 / Use intersection of columns
Concatenate -> F6 -> F7 -> Concatenated table

- 두 테이블에 모두 포함된 행인 Customer ID 변수만 출력 / Skip Rows의 경우 830행
- 두 테이블에 모두 포함된 행인 Customer ID 변수만 출력 / Append Suffix의 경우 921행


그룹화
● 그룹화할 범주 변수를 선택
● Node : GroupBy
- 각각의 범주마다 집계할 변수와 집계 방법 설정
- 계산한 테이블 반환

ex)
Groupby 노드 -> F6에서 그룹할 컬럼을 선택할 수 있다.
F6에서 Manual Aggregation을 클릭
● Aggregation
- Concatenates : 각 범주에 포함되는 값들을 차례대로 나열


* ShipRegion의 Concatenates는 한 열로 쭉 나열되는 듯
- Count : 각 범주에 포함되는 값들의 갯수


* 어떤 행을 넣던 Rows가 830이기 때문에 803이 나옴
- First : 각 범주에 포함되는 첫 번째 행의 값


* ShipCountry의 첫 행은 France
- Last : 각 범주에 포함되는 마지막 행의 값


* ShipCountry의 마지막 행은 USA
- List : 각 범주에 포함되는 값들을 모아서 list 형식으로 표현


*ShipVia의 행은 1,2,3밖에 없어서 List로 표현되는 줄 알았는데, ShipCountry 행은 수십개가 있지만 France, Germany, Brazil로 3개만 표현되지만 아마 더 많은 노드를 연결하면 리스트가 다 보일 것?
- Mean : 각 범주에 포함되는 값들의 평균값

- Percent : 각 범주에 포함되는 값들이 차지하는 비율


* 값들이 다 있어도, missing value가 있어도 100으로 나오넹?
- Set : 각 범주에 포함되는 값들의 고유 집합


* 음 ㅎㅎ
- Mode : 각 범주에 포함되는 값들 중 가장 빈도가 높은 값을 표현


* ShipCountry 행에서 가장 빈도가 높은 값(가장 주문을 많이 한 나라)는 Germany
- Unique count : 각 범주에 포함되는 값들 중 고유한 값의 개수


* EmployyeID의 수는 총 9개이고 / ShipCountry를 통해 총 21개 국이 주문한 것을 알 수 있다.

● Aggregation priority / 집계 우선순위
- Manual aggregation -> pattern-based aggregation -> type-based aggregation
ex)

Groupby -> F6 -> Groups에서 Country를 그룹변수로 둔다.

Manual Aggregation에서
CustomerID를 add하고 aggregation은 Unique count로
Freight를 add하고 aggregation은 Mean으로
City를 add하고 aggregation은 Mode로 한다.

Pattern-based aggregation에서 Add를 누르고 Search pattern은 S*를 하고 RegEx는 체크 해제를 한 후 aggregation은 List로 한다.

마지막으로 Type-based aggregation은 Data and Time을 add하고 aggregation은 First로 한다.
그리고 하단에 Advanced settings에서 Column naming에서 Column name(aggregation method)로 설정한 뒤 apply 한다.

F7 -> Group table을 한다.
도시에 대해서 고객ID의 유니크 개수와 Frieght의 평균값, 그리고 City 중 가장 빈도가 높은 곳을 표현 하였다. Row0은 Column을 추가해서 최종 값들을 볼 수 있는데 예시와 달리 Data and Time이 안보여서 확인 中
